CS 352 Lecture 36 – Pipelining
Dear students,
We begin today with a short baking lesson that will demonstrate the need for processing instructions differently. Suppose I need a lot of cookies. Ignoring the setup costs, suppose it takes me 15 minutes to scoop out 12 balls of dough and plop them onto a baking sheet. These then cook for 30 minutes, at which point I plop down another batch of cookies and bake them, all for a solid 8 hours. We have this progression:
| 15 | 30 | 15 | 15 | 30 | 15 | … |
What is the latency in this situation? How long does it take for a cookie to go from a twinkle in my eye to realization? Well, there are 15 minutes of plopping and 30 minutes of baking. So the latency is 45 minutes. What is the throughput over the course of our 8-hour day? Recall that throughput is the number of requests/operations we can perform in a given span of time. 8 hours is 480 minutes (no bathroom breaks; that way we don’t have to wash our hands more than once). 480 minutes divided by 45 minutes per sheet is ~10.67 sheets, or 128 cookies in a day.
Is that good? Is “Is that good?” a good question? A better question would be, “Can the latency or throughput be improved?” We are currently underutilizing our resources. Let’s try overlapping the plopping with the baking.
| time chunk | 1 | 2 | 3 | 4 | 5 | 6 |
|---|---|---|---|---|---|---|
| sheet 1 | 15 | 30 | ||||
| sheet 2 | 15 | 30 | ||||
| sheet 3 | 15 | 30 | ||||
| sheet 4 | 15 | 30 | ||||
| … | … | … |
What is the latency now? Well, a single sheet still takes 45 minutes. What is the throughput? Once the ball gets rolling, new cookies emerge from the oven every 30 minutes. But to prime the system, we need to pay 15 minutes of setup. So, our overall time in which sheets emerge is 480 – 15 = 465. Within those 465 minutes, we get sheets every 30 minutes, so 465 divided by 30 is 15.5, or 186 cookies in a day.
The overlapping of steps like this is called pipelining. In computing, we define pipelining as the execution of multiple instructions at a time on a single processor, made possible by partitioning the processor hardware into stages. To avoid structural hazards, each overlapping instruction touches a different part of the hardware.
Pipelining is not the only way to increase performance. How else can we do it?
- Decrease latency. A better oven might cook faster, and a better me might plop faster.
- Expand resources. One oven can only do so much. Why not use two or three?
Regarding the first of these, check out this picture. What observations can you make from this graph?
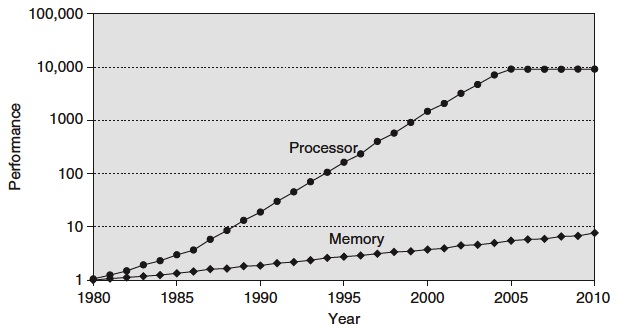
I see a few:
- Processor speed improvements have dominated memory speed improvements. This makes caching extremely important. The overall performance of the CPU, no matter how fast it gets, is bound up in the performance of the memory from which it reads. Cache keeps it from having to read memory very often.
- Processor performance stagnated around 2004, the year when Intel ran into what’s called the power wall. The processor generated so much heat that the project was canned. So that performance could continue to increase, they and the rest of industry shifted their efforts into bundling processors together. The age of multicore dawned. But eking out performance from multiple cores is a little harder. There are fewer abstractions of multiple cores.
The processor is a long tunnel, and we’re going to let multiple instructions travel through at once. How exactly we partitition it varies, but in general, we usually see five or so stages:
- fetch, in which the instruction pointed to by the program counter is retrieved from memory
- decode, in which the bits of the fetched instruction are “parsed” to figure out what operation is to be executed and which registers or memory cells are referenced
- execute, in which the ALU does its thing based on the control signals from the decoded instruction
- memory, in which the address specified by a load/store is read from or written to
- writeback, in which the destination register is updated
We will demonstrate visually how a few example programs are pipelined.
Consider program A:
ldr r2, [r0, #40] add r3, r9, r10 sub r4, r1, r5 and r5, r12, r13 str r6, [r1, #20] orr r7, r11, #42
Consider program B:
add r1, r4, r5 and r8, r1, r3 orr r9, r6, r1 sub r10, r1, r7
Consider program C:
loop: add r0, r0, #1 cmp r0, r2 bne loop bl exit
Program B introduces a data hazard, a read-after-write. Since our instructions now overlap, this is a big issue. We don’t want to read a register that hasn’t yet been written! Program C introduces a control hazard, where we don’t know which instruction is next to execute. Such hazards can severely disrupt our pipelining. Next time we’ll look at ways to overcome or minimize these issues.
Here’s your TODO list for next time:
- Read the Future of Computers, parts 1, 2, and 3. On a quarter sheet, jot down 2-3 questions, observations, or predictions about the future of computers.
See you next class!

P.S. It’s Haiku Friday!
The bank line moved slow
Celeron was at the front
He was strapped for cache