CS 330 Lecture 34 – Lexing
Dear students,
Okay, we’re on a quest to design our own programming language. Usually you’re supposed to start this kind of learning by writing a calculator. I couldn’t bring us to do that. Instead we’re going to design a language for drawing art based on primitive shapes. And instead of me foisting a language upon you, why don’t you design the language? However, you shouldn’t design a language until you’ve already programmed in it. So here’s your task:
Write a short program that draws something using simpler primitive shapes. What do you want to be able to express? In what form?
We’ll look at a few examples and try to agree upon a syntax. Then we’ll start to tackle interpreting programs written in this language. We break interpreting up into two steps:
- Lexing, in which we decompose the source code into its “atoms”. The input is the source code. The output is a flat sequence of tokens.
- Parsing, in which we construct a model of our program. The input is the stream of tokens. The output is a meaningful representation of the program. If we store this representation of our program to disk, we have a compiler. If we execute it immediately, we have an interpreter.
But today, we don’t deal with meaning. We just want to rip our program into a thousand tiny pieces. Meaningless pieces. But not individual characters. That’s too fine-grained. We want the tokens. What are tokens? Literals, identifiers, keywords, operators, and separators.
We’ll draw a DFA for capturing tokens in our language. It may or may not look something like this:
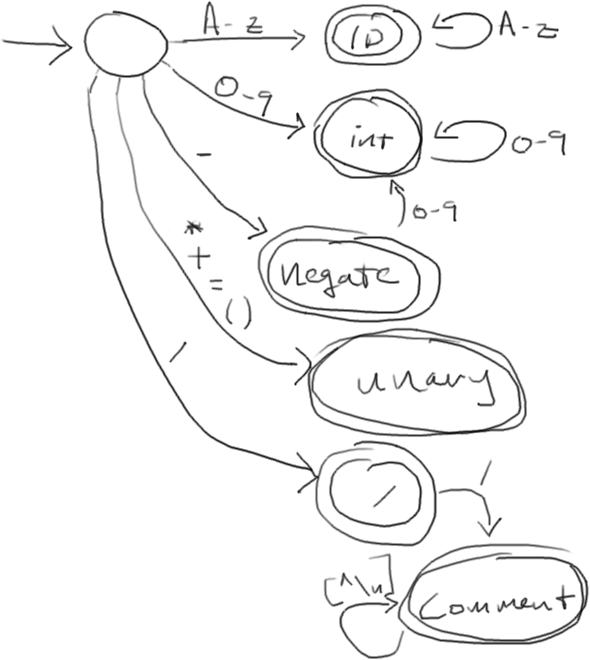
You’re probably thinking, “This isn’t code, so how does this help me!” Well, it turns out that we can model our code around this DFA, and it’ll feel like we’re doing it right.
We’ll build our interpreter in Javascript, because it is a language that we cannot escape. Our class that does the tokenizing or lexing will be called Lexer. But Javascript doesn’t support classes like we’re used to. Instead we just write a function that acts like a constructor and builds up the instance:
function Lexer(program) {
// Private stuff (local var and function definitions)
...
// Public stuff (starts with this)
this.lex = function() {
...
}
}
Clients of Lexer will use it like so:
var lexer = new Lexer(src);
var tokens = lexer.lex();
tokens.forEach(function(token) {
console.log(token);
});
We’ll also create a Token class to represent the pieces of our program:
function Token(type, src) {
this.type = type;
this.src = src;
}
That first parameter represents what kind of a token we have. A string literal, a plus sign, a left parenthesis, and what have you. What should be the type of type? An enum, probably. Sadly, Java doesn’t support enums. We’ll just create a set of strings that we vow to never change:
var INTEGER = 'INTEGER';
var IDENTIFIER = 'IDENTIFIER';
var EOF = 'EOF';
var LEFT_PARENTHESIS = 'LEFT_PARENTHESIS';
var RIGHT_PARENTHESIS = 'RIGHT_PARENTHESIS';
var PLUS = 'PLUS';
var TIMES = 'TIMES';
var ASSIGN = 'ASSIGN';
var MINUS = 'MINUS';
var DIVIDE = 'DIVIDE';
var SQUARE = 'SQUARE';
var CIRCLE = 'CIRCLE';
Okay, now we get to the heart of our algorithm: the lex function. It will capture the machinery of our DFA. This will be a little different than our DFAs from the other day, however, because our goal here is to gobble up many tokens—not just one. So, once it lands in an accepting state, it will emit the token that it has seen so far. Then it’ll start back over in the starting state with the remaining characters in our source code.
To manage complexity, any time we have a “wild” state, one with multiple transitions in or out, we’ll create a helper function that corresponds to that state.
In pseudocode we compose our algorithm as follows:
while not all characters are consumed
switch on next character
case (
consume
emit LEFT_PARENTHESIS token
case )
consume
emit RIGHT_PARENTHESIS token
case +
consume
emit PLUS token
case letter
call identifier
case number
call integer
case -
call minus
...
emit EOF token
Let’s tackle the implementation in this order:
- Write a
hasmethod that asserts the next character matches a regular expression - Write a
consumefunction that advances one character and adds it the token that’s currently being matched - Write an
emitTokenfunction that appends a token to our list - Handle single character tokens
- Handle integers
- Handle identifiers
- Handle whitespace
- Handle negative numbers and subtraction
- Handle comments
Here’s what we’ll use for has:
this.has = function(regex) {
return regex.test(command.charAt(iToRead));
}
We’ll need a bookmark into our source code pointing to the first unconsumed character. We can declare it as a private instance variable right inside the Lexer constructor:
var iToRead = 0;
The consume function will throw the character we’re looking at the token we’ve assembled so far and push us on to the next:
this.consume = function() {
tokenSoFar += command.charAt(iToRead);
++iToRead;
}
We’ll need to track the token being built up so far as an instance variable:
var tokenSoFar;
And initialize it in lex!
Once we reach an accepting state, we’ll need to package up the symbols into a token:
var tokens;
...
this.emitToken = function(type) {
tokens.push(new Token(type, tokenSoFar));
tokenSoFar = ''; // reset the DFA
}
With these helpers in place, we can start to write lex to handle the single-character tokens:
iToRead = 0; // begin at the beginning
tokenSoFar = ''; // having seen nothing
tokens = [];
while (iToRead < program.length) {
if (this.has(/\+/)) {
this.consume();
this.emitToken(PLUS);
} else if (this.has(/\*/)) {
this.consume();
this.emitToken(MULTIPLY);
} else if (this.has(/\)/)) {
this.consume();
this.emitToken(LEFT_PARENTHESIS);
} else if (this.has(/\(/)) {
this.consume();
this.emitToken(RIGHT_PARENTHESIS);
} else if (this.has(/=/)) {
this.consume();
this.emitToken(ASSIGN);
} else {
console.log('You fell into the tomb of the unknown token: ' + program.charAt(iToRead));
}
}
return tokens;
We can test this with a little HTML:
<textarea id="editor" rows="10" cols="50" style="font-size: 24pt;"></textarea><br>
<script src="shaper.js"></script>
And a listener defined in Javascript:
var editor = document.getElementById('editor');
editor.onchange = function() {
var lexer = new Lexer(editor.value);
var tokens = lexer.lex();
tokens.forEach(function(token) {
console.log(token);
});
}
Does it work? I hope so!
Now let’s augment our if-ladder to handle integer literals:
else if (this.has(/\d/)) {
this.integer();
}
And we’ll add a function for this more complex state:
this.integer = function() {
while (iToRead < program.length && this.has(/\d/)) {
this.consume();
}
this.emitToken(INTEGER);
};
Let’s handle identifiers similarly:
else if (this.has(/[A-Za-z]/)) {
this.identifier();
}
However, what constitutes a legal identifier in most programming languages? Can we name a variable for? Or if? No. These are keywords. Instead of tweaking our DFA to have special states for keywords, it’s common practice to special case them after you’ve lexed out an identifier:
this.identifier = function() {
while (iToRead < program.length && this.has(/[A-Za-z]/)) {
this.consume();
}
if (tokenSoFar == 'square') {
this.emitToken(SQUARE);
} else if (tokenSoFar == 'circle') {
this.emitToken(CIRCLE);
} else {
this.emitToken(IDENTIFIER);
}
};
We should be able to lex integer literals and identifiers now. Let’s try a program that has both!
56 foo
It fails on the whitespace. Our lexer must be ready for that too! But hey, whitespace isn’t significant in many languages, so there’s really no reason to emit a token for it. We just consume and toss any spaces or tabs:
else if (this.has(/[ \t]/) {
this.consume();
tokenSoFar = '';
}
How about -? This operator is the bane of lexing. Sometimes it’s a unary operator, negating its operand. Other times its a binary operator. We’ll determine how to handle it by deferring to a helper:
else if (this.has(/-/)) {
this.minus();
}
The helper function will peek ahead to figure out what kind of minus it is:
this.minus = function() {
this.consume();
if (this.has(/\d/)) {
this.integer();
} else {
this.emitToken(MINUS);
}
}
How about division? Well, if we see two slashes, maybe we’re looking at a comment? We’ll need to solve this similarly. First, our condition in lex:
else if (this.has(/\//)) {
this.divide();
}
The helper function will peek ahead to distinguish between the mathematical operator and a comment. Comments, like whitespace, we can discard, as they will have no impact on the interpretation of our program.
this.divide = function() {
this.consume();
if (this.has(/\//)) {
this.consume();
while (this.has(/[^\n]/)) {
this.consume();
}
tokenSoFar = '';
} else {
this.emitToken(DIVIDE);
}
}
That rounds out our lexer, the first stage of getting our computer to understand us. We have broken the program up into byte-size pieces. Next time we’ll look at parsing, which will figure out what we’re actually trying to say with these utterances. See you then!

P.S. It’s Haiku Friday!
I lexedheadjust fine
But I got stuck inbody
Right at the: