CS 330: Lecture 3 – State Machines and More Regex
Dear students,
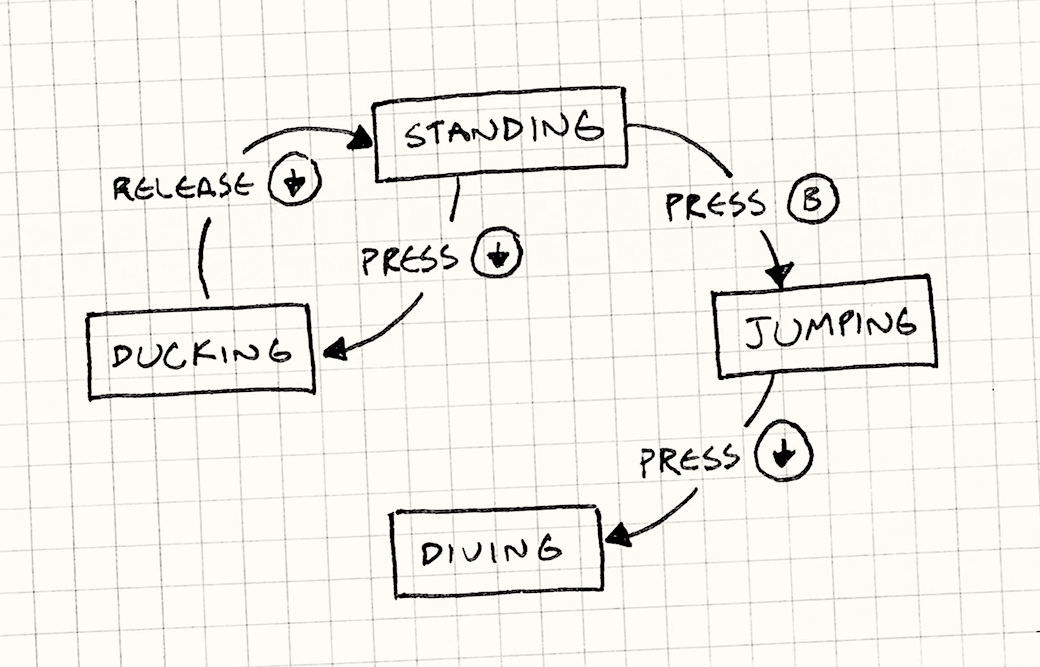
Before diving into code, let’s be computer scientists for a minute. We’re going to consider a model of computation called a deterministic finite automaton (DFA). A DFA is a special case of a state machine. Here’s a state machine used to model an avatar’s state in a game:
And one for water:
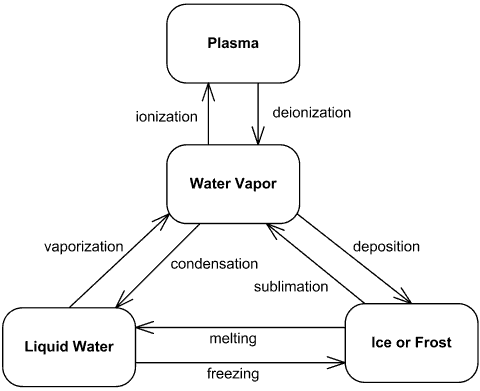
What are the key elements of a state machine? The states themselves, and the transitions between them.
DFAs are state machines used to match text that falls into the “language” that the machine recognizes. For example, we might build a machine that accepts only strings of all capital letters, only lists of numbers separated by commas, or only four-digit PINs. To build a DFA, we need to know a few things:
- a set of states that we can be in
- the set of symbols that we might encounter
- a subset of accepting states
We tell if a string is in a DFA’s language by feeding it the string. It bites off a character at a time. Each character takes the machine into a new state. If the string winds up in a final or accepting state when all the characters have been consumed, that string is said to be in the DFA’s language. If we end up in any other state, the string is rejected.
Let’s create a few DFAs:
- Strings over the alphabet
[c]that have even length. - Strings over the alphabet
[dog]likedog,doog,dooog, and so on. - Strings over the alphabet
[01]in which all 0s appear before all 1s. - Strings over the alphabet
[01]with an even number of 0s and an even number of 1s. - Strings over the alphabet
[01]in which any 0 is preceded directly by at least two 1s. - Strings that are integer literals.
- Strings that are floating point literals.
Languages that can be recognized by a DFA are called regular. You cannot build a DFA over the alphabet [()] that matches all strings of balanced parentheses. I invite you to try, but you will fail. Generally, any language that has recursive elements is not regular. Regular expressions are a textual notation of DFAs, and that is why they are called regular. When the Ruby interpreter encounters a regex in our code, it builds up a DFA and starts following this algorithm for =~:
function =~(s, regex)
dfa = build(regex)
for each index i in string s
portion = s.substring(i)
if dfa accepts portion
return true
return false
The scan method we saw last time extends this idea to accumulate up the results instead of just bailing at the first match.
Regex are not just boolean machines, however. Sometimes we want to extract a portion of the matching text. If we parenthesize the pattern that matches the text we care about, the matching text will be saved in a variable whose identifier is the parenthesized group’s 1-based serial number. For example:
expression =~ /(\d+)([-+*\/])(\d+)/
a = $1
operator = $2
b = $3
To close off today, let’s solve a few problems using scan:
- Extract the URLs from all
imgelements. - List all the HTML tags in a file.
- Find all the statements that don’t end in a semi-colon. (As a proxy, we’ll say all lines that have code on them that don’t end in a curly brace, comma, or semi-colon.)
- Find all the public method names in a Java source file.
Here’s your TODO list for next time:
- Optional: There’s a software design pattern based on the state machine. You may be interested in seeing how it’s applied to modeling a player.

P.S. It’s time for a haiku!
I was in DESPAIR
But Friday bumped me along
To MELANCHOLY
P.P.S. Here’s the code we wrote together:
calcul8r.rb
#!/usr/bin/env ruby
expr = ARGV[0]
if expr =~ %r{(\d+)\s*([/%])\s*(\d+)}
a = $1.to_i
operator = $2
b = $3.to_i
if operator == '/'
puts a / b
else
puts a % b
end
end