CS 330: Lecture 19 – Vtables
Dear students,
Did you know that in the early days of C++, it was just a thin veneer over C? Classes were just syntactic sugar. We might have had a class that looked like this:
class Hero {
public:
Hero(char *name, int hp) {
this->name = strdup(name);
this->hp = hp;
}
void cure(int boost) {
hp += boost;
}
private:
char *name;
int hp;
}
This code would get compiled down to C, where classes weren’t a thing. But C does have structs, so Hero would get turned into one of those:
struct Hero {
char *name;
int hp;
}
What about the methods of Hero? They’d get turned into regular C functions:
void cure(struct Hero *hero, int boost) {
hero->hp += boost;
}
Notice how the invoking object becomes the first parameter. But it wasn’t called hero. It was called this:
void cure(struct Hero *this, int boost) {
this->hp += boost;
}
What happened with code like this?
Hero *frank = new Hero("Frank", 260);
It turned into code like this:
void initialize_hero(struct Hero *this, char *name, int hp) {
this->name = strdup(name);
this->hp = hp;
}
int main() {
struct Hero *frank = (struct Hero *) malloc(sizeof(struct Hero));
initialize_hero(frank, "Frank", 260);
// ...
}
Those two lines in main were particular dear to Bjarne Stroustrup, the originator of C++. In C, it was very easy to allocate space for an instance of a data structure but then forget to initialize it. Stroustrup believed that allocation and initialization should not be separate steps, that “resource acquisition is initialization” (RAII). His idea was a reasonable one, and it has been adopted by the modern languages in widespread use.
Eventually, C++ got distinct enough that it got its own compiler and went directly from C++ to machine code. One of the features that made it significantly different was subtype polymorphism.
For subtype polymorphism to work in languages like Java and C++, we need some for way for each object to carry around some information to help us figure out what method to call at runtime. What exactly is that information and how does the runtime decision—the dynamic dispatch—get made? Computer graphics pioneer Jim Blinn wrote a column in 1990s when C++ was gaining in popularity, and he dismissed polymorphism, saying he’d doing something like that in Fortran for the longest time. Here’s his polymorphism in Fortran:
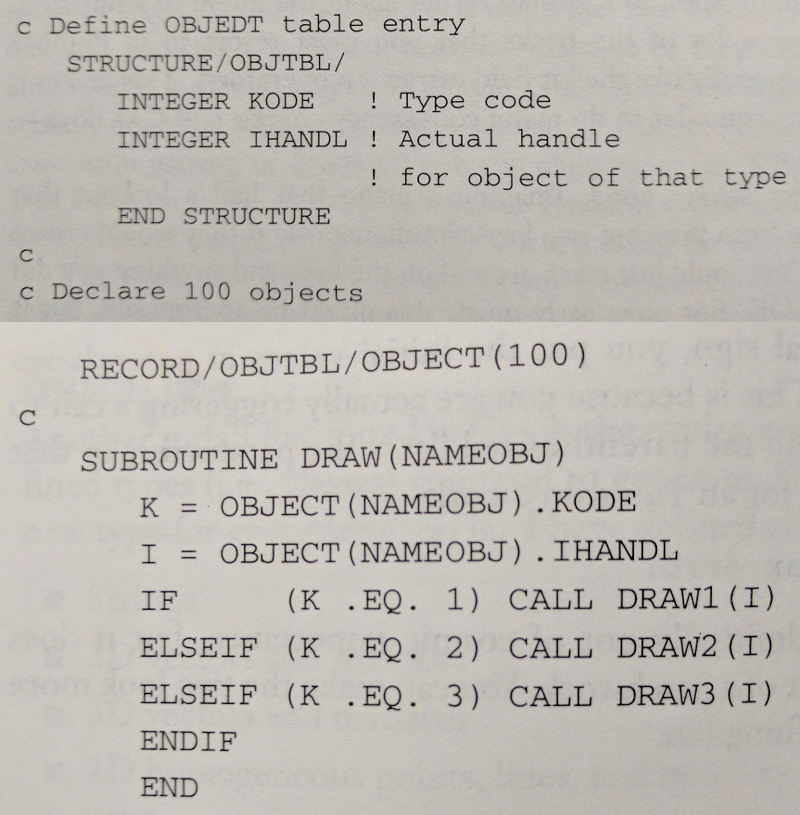
Subroutine DRAW is the conductor code. It walks through a conditional ladder, inspects a type tag, and dispatches accordingly. This looks a lot like our dynamic typing system we wrote in C.
If this was how dynamic dispatch was implemented, its designer would have been eaten alive on Reddit and Stack Overflow. Why? For one, the conductor code is full of conditional statements. We saw in computer architecture that conditional statements thwart pipelining. For two, every time we add a new type to our hierarchy, we have to go back to the conductor code and update it. We’d really like to avoid touching code once it’s working. We tend to mess stuff up. There’s that saying, “separate that which changes from that which doesn’t.” This is why we make battery compartments. This is why we use domain names instead of IP addresses. This is why oil filters are always in locations that are easy to access. (Right?)
Thankfully, dynamic dispatch is implemented differently.
Look at the memory footprint of some classes. We’ll start with an int wrapper:
#include <iostream>
class A {
public:
A(int a) :
a(a) {
}
void foo() {}
private:
int a;
};
int main(int argc, char **argv) {
A a(3);
return 0;
}
Let’s compile this and inspect a with the debugger. Here’s the g++/gdb magic that makes that possible:
g++ -std=c++11 -g footprint.cpp
gdb ./a.out
(gdb) break main
(gdb) run # run until breakpoint
(gdb) n # step through next statement
(gdb) print sizeof(a) # Probably 4 or 8
(gdb) x/4b &a # Examine the 4 bytes of a
When I run this on my macOS laptop, I get this output:
(gdb) print sizeof(a) $1 = 4 (gdb) x/4b &a 0x7fff5fbfe918: 3 0 0 0
What’s the endianness of my machine? What happens when we add some more state? Like an array of characters:
class A {
public:
A(int i) :
i(i) {
}
private:
char cs[] = {'a', 'b', 'c'};
int i;
};
When I run this on my macOS laptop, I get this output:
(gdb) print sizeof(o) $1 = 8 (gdb) x/8b &o 0x7fff5fbfe918: 97 98 99 0 3 0 0 0
The char[] is padded so that i has a word-aligned address.
Let’s add a subclass:
class B : public A {
public:
B(int i, float f) :
A(i),
f(f) {
}
private:
float f;
};
int main(int argc, char **argv) {
A a(3);
B b(10, 3.14159);
return 0;
}
Class A hasn’t changed. But let’s inspect our instance of B:
(gdb) print sizeof(b) $1 = 12 (gdb) x/12b &b 0x7fff5fbfe908: 97 98 99 0 3 0 0 0 0x7fff5fbfe910: -48 15 73 64
This output tells us that the first bytes of a B instance are its A foundation. We also see the wild bytes of the float come after.
Notice that no space in these objects is reserved for code. Code doesn’t live in the object; it is shared across all objects and lives in the text segment. We package code and data together in an object-oriented, but that’s not how things are organized at the level of the machine.
Let’s make foo virtual function:
virtual void foo() {}
What effect does this have on a and b? Let’s check:
(gdb) print sizeof(a) $1 = 16 (gdb) print sizeof(b) $2 = 24 (gdb) x/16b &a 0x7fff5fbfe910: 32 16 0 0 1 0 0 0 0x7fff5fbfe918: 97 98 99 0 3 0 0 0 (gdb) x/24b &b 0x7fff5fbfe8f8: 72 16 0 0 1 0 0 0 0x7fff5fbfe900: 97 98 99 0 3 0 0 0 0x7fff5fbfe908: -48 15 73 64 0 0 0 0
It’s not clear to me why b has those extra 4 bytes at the end. Why couldn’t it have been 20 bytes instead of 24? It was given 12 bytes before, which doesn’t seem to have any better alignment than 20.
More interesting however are the initial 8 bytes. That, my friends, is the a pointer to each class’s vtable, the vehicle by which fast subtype polymorphism happens. Let’s examine a class hierarchy (courtesy of Stroustrup) and see how these virtual tables are laid out:
class A {
public:
virtual void f();
virtual void g(int);
virtual void h(double);
void i();
int a;
};
class B : public A {
public:
void g(int);
virtual void m(B*);
int b;
};
class C : public B {
public:
void h(double);
virtual void n(C*);
int c;
}
The vtable of A looks like this:
| index | Function | Address |
|---|---|---|
| 0 | f | &A::f |
| 1 | g | &A::g |
| 2 | h | &A::h |
Method i gets no entry, because it is not virtual.
The vtable of B looks like this:
| index | Function | Address |
|---|---|---|
| 0 | f | &A::f |
| 1 | g | &B::g |
| 2 | h | &A::h |
| 3 | m | &B::m |
Class B overrides g and adds m. Its other entries just point to the versions from A.
The vtable of C looks like this:
| index | Function | Address |
|---|---|---|
| 0 | f | &A::f |
| 1 | g | &B::g |
| 2 | h | &C::h |
| 3 | m | &B::m |
| 4 | n | &C::n |
These vtables are stored once per class—they’re static. Each instance of A, B, or C has an implicit instance variable pointing to its class’ vtable. We’ll call that member vptr. An instance of A is laid out like this in memory:
| vptr |
| a |
An instance of B is laid out like this in memory:
| vptr |
| a |
| b |
An instance of C is laid out like this in memory:
| vptr |
| a |
| b |
| c |
Now, suppose we have a piece of conductor code that takes in a pointer to A, but under the hood the object is an instance of C:
void conduct(A *p) {
p->g(11);
}
What exactly has to happen here to get the right code running?
- We must conjure up
p‘svptr. - In the table pointed to by
p->vptr, we must locate the address of the code forg, which has index 1. - We must call that code with both the invoking object and 11 as parameters.
Under the hood, this invocation turns into a crazy indirect memory lookup. We get a function pointer from the vtable pointed to by the object and call it:
(*(*p->vptr)[1])(p, 11);
So, subtype polymorphism is made fast at runtime through a table lookup. No conditionals are needed. Is this indirection free? No, because there are memory reads. Will these memory reads be fast? The vtables will likely be stored in cache if they are frequently accessed. They are small and there’s only one per class. The object is also likely to be in cache if we’re operating on it.
C++ isn’t the only language to use vtables. Consider this statement from the Java Virtual Machine specification:
The Java Virtual Machine does not mandate any particular internal structure for objects.In some of Oracle’s implementations of the Java Virtual Machine, a reference to a class instance is a pointer to a handle that is itself a pair of pointers: one to a table containing the methods of the object and a pointer to the Class object that represents the type of the object, and the other to the memory allocated from the heap for the object data.
We have just unraveled the great mysteries of runtime polymorphism. Let’s call it a day.
Here’s your TODO list for next time:
- Complete your exam before Friday at 3 PM.
See you then!

P.S. It’s time for a haiku!
We’ve got vtables
Dad to me’s not Dad to you
Or maybe he is
P.P.S. Here’s the code we wrote together: