CS 430: Lecture 8 – Activation
Dear students,
Today we take a foray into a technical topic: the mechanics of calling functions. We might think this is information that is pretty well hidden from us when we’re writing in a high-level language. But abstractions leak. The way that functions are called bubbles up into the design of our languages. Having some awareness of what’s happening under the hood will help you write safe and faster code and will help you empathize with the designers of a language.
Managing Function State
Your mind is consumed by the latest programming assignment. Then someone rings your doorbell. You panic. Dirty laundry carpets the floor. Dirty dishes fill the sink and counter. Your roommate’s pizza crusts have been squirreled away in random places. Immediately you begin stashing things away and switching over your mind to accommodate this new activity of having company over. The exact same thing happens when you call a function. Let’s talk about the mad scramble that accompanies a function call using the ubiquitous C calling conventions.
The calling function will be paused while the called function executes, but the calling function’s state must be preserved so it can be restored when the called function finishes. Only one function is active at a time, so the memory can be represented as a stack structure. The current function’s local state is at the top of the stack. In many operating systems, a process is laid out like this in memory:
| address | segment |
|---|---|
| high | stack |
| … | |
| heap | |
| globals | |
| low | code |
Technically, the stack grows downward, with its top at the bottom. A called function will get its own state below the caller’s on the stack. That state is called a stack frame or activation record.
Two registers are used to indicate the extent of a function’s stack frame. Register %ebp is the base pointer or frame pointer. It points at the start of the function’s memory. Your book calls it the environment pointer (EP). This pointer is fixed in place during the function’s execution. The register %esp points at the last allocated memory cell of the stack. It will grow and shrink as the function allocates or deallocates stack memory. We change %esp either directly with a subl $NBYTES, %esp instruction or indirectly via pushl RVALUE or popl LVALUE instructions.
Calling Without Parameters
Let’s see what happens when a call to a 0-arity function is encountered. Consider this C code:
int rand();
int f() {
return 3 + rand();
}
We compile this down to assembly, not machine code, to see what the machine does to implement the function call. This invocation of gcc will produce the assembly:
gcc -fno-asynchronous-unwind-tables -m32 -o assembly.s -S -O0 file.c
And here’s a portion of the assembly that results:
calll _rand
addl $3, %eax
What do you notice about this code, apart from the many Ls in calll?
The return value from rand is available in %eax. This is generally how simple data is returned from functions. Sometimes the return value might be sent along as an out parameter. Other times the return value might be sent back using other registers. Function f tacks 3 onto %eax, which will also serve as the return value of f.
One thing that you can’t tell from this code is that the calll instruction implicitly does something like this:
pushl ADDRESS-OF-NEXT-INSTRUCTION
movl ADDRESS-OF-FUNCTION, %eip
The return address is pushed onto the stack so the CPU can navigate back to the caller when rand finishes. Sometimes malicious programs will take advantage of this and try to write a different address into the stack, one that leads to code the malicious program has inserted somewhere else in memory. Register %eip is the instruction pointer or program counter. We can’t write to it it directly in x86. Instead we use call or jmp.
Here’s the code in its fuller context:
# Prologue
pushl %ebp
movl %esp, %ebp
subl $8, %esp
calll _rand
addl $3, %eax
addl $8, %esp
# Epilogue
popl %ebp
retl
The first few lines constitute the prologue, the setup code that all functions include. We push the caller’s base pointer onto the stack. Your book calls this the dynamic link. With that safely archived, we update the base pointer for f so that it points at the location of the caller’s base pointer.
The subl instruction allocates 8 bytes of space on the stack. But there are no local variables. What gives? Well, on some machines, there’s an expectation that stack frames must be aligned on addresses that are multiples of 16. A couple of things have already happened prior to this code that messed up that alignment. Before f was called, the 4-byte return address of the caller was pushed. Then the 4-byte %ebp was pushed in the prologue. That moved us to an 8-byte alignment. The compiler inserts an additional and otherwise useless 8 bytes of space so that the stack frame for rand is aligned to a 16-byte address.
At the end, we add 8 bytes back on to the stack pointer. This effectly frees the stack memory. There’s no wiping the data. The values are still there, available for inspection by malicious code.
Then we reach the epilogue, the sequence of instructions that all functions follow to close out the function call. We grab the caller’s base pointer off the stack and restore it to the register. The retl instruction grabs the caller’s return address of the stack and jumps to it. Effectively it is this instruction:
popl %eip
Calling With Parameters
We’ve seen how a function’s return value is managed. Let’s consider this call to a function with parameters:
void g(int a, int b, int c);
void f() {
g(5 + 10, 20, 30);
}
This code compiles down to this assembly:
# Prologue...
subl $24, %esp
movl $5, %eax
addl $10, %eax
movl %eax, (%esp)
movl $20, 4(%esp)
movl $30, 8(%esp)
calll _g
addl $24, %esp
# Epilogue...
Actually, it’s not quite the assembly that I get. Even with no optimizations, gcc will add the 5 and 10 together automatically and not generate the addl instruction. I inserted it manually. These several things are observed in this code:
- A whopping 24 bytes are pushed onto the stack this time. This again is to align the stack frame to a 16-byte address. 8 bytes wouldn’t be enough to hold the three parameters, so we go to the next multiple 8 + 16 = 24.
- The parameter expressions are evaluated eagerly in left-to-right order before the function is called.
- The parameter values are placed on the stack in reverse order. The first parameter is nearest to the dividing line between stack frames.
- Cleaning up the stack is again a matter of just updating the stack pointer.
Accessing Parameters and Local Variables
We’ve seen the mechanics setting up and tearing down a function. Let’s look now at how parameters and local variables are accessed. Consider this C function which accepts two parameters and allocates two local variables:
int sum(int a, int b) {
int x = a + b;
int y = x + 13;
return y;
}
The compiler might translate this function into this assembly:
# Prologue...
subl $8, %esp
movl 8(%ebp), %edx /* edx = a */
addl 12(%ebp), %edx /* edx += b */
movl %edx, -4(%ebp) /* x = edx */
addl $13, %edx /* edx += 13 */
movl %edx, -8(%ebp) /* y = edx */
movl $edx, %eax
# Epilogue...
We can make the following observations about how local data is accessed:
- The base pointer acts as a foothold whereby all parameters and stack variables are accessed. Recall that
%ebpitself points to the location of the caller’s archived base pointer. 4 bytes above this is the caller’s return address. - 8 bytes above the archived base pointer is the first parameter. 12 bytes above is the second parameter. And so on.
- 4 bytes below the archived base pointer is the first local variable. 8 bytes below is the second local variable. And so on.
Calling Conventions in Brief
In summary, the following steps happen on a function call:
- In the caller, evaluate the parameters in left-to-right order.
- In the caller, push the parameters onto the stack in reverse order.
- In the caller, push the return address on the stack.
- In the callee, push the caller’s base pointer on the stack.
- In the callee, allocate space for local variables by adjusting
%esp. - Do the work of the callee.
- In the callee, deallocate the local variables.
- Pop the caller’s base pointer.
- Pop the caller’s return address and jump to it.
- Release the memory consumed by the parameters.
There’s a step we have not discussed. Only so many registers available, and functions will have to coordinate how they change them so they don’t clobber each other’s state. In x86, the convention is that a function is free to modify %eax, %ecx, or %edx, because the caller has preserved its copies on the stack before the call. If the function needs to use other registers, it must push the caller’s values of these registers on the stack and then restore them as the function’s finish. Preserving registers on the stack like this is sometimes called spilling.
Static Scoping
All of the discussion above is focused on C and x86. C takes a very simple view of functions: they are all defined at the top-level. Many languages allow functions to nest. If an inner function references variables from an outer function, we must have a scheme for accessing another function’s stack frame.
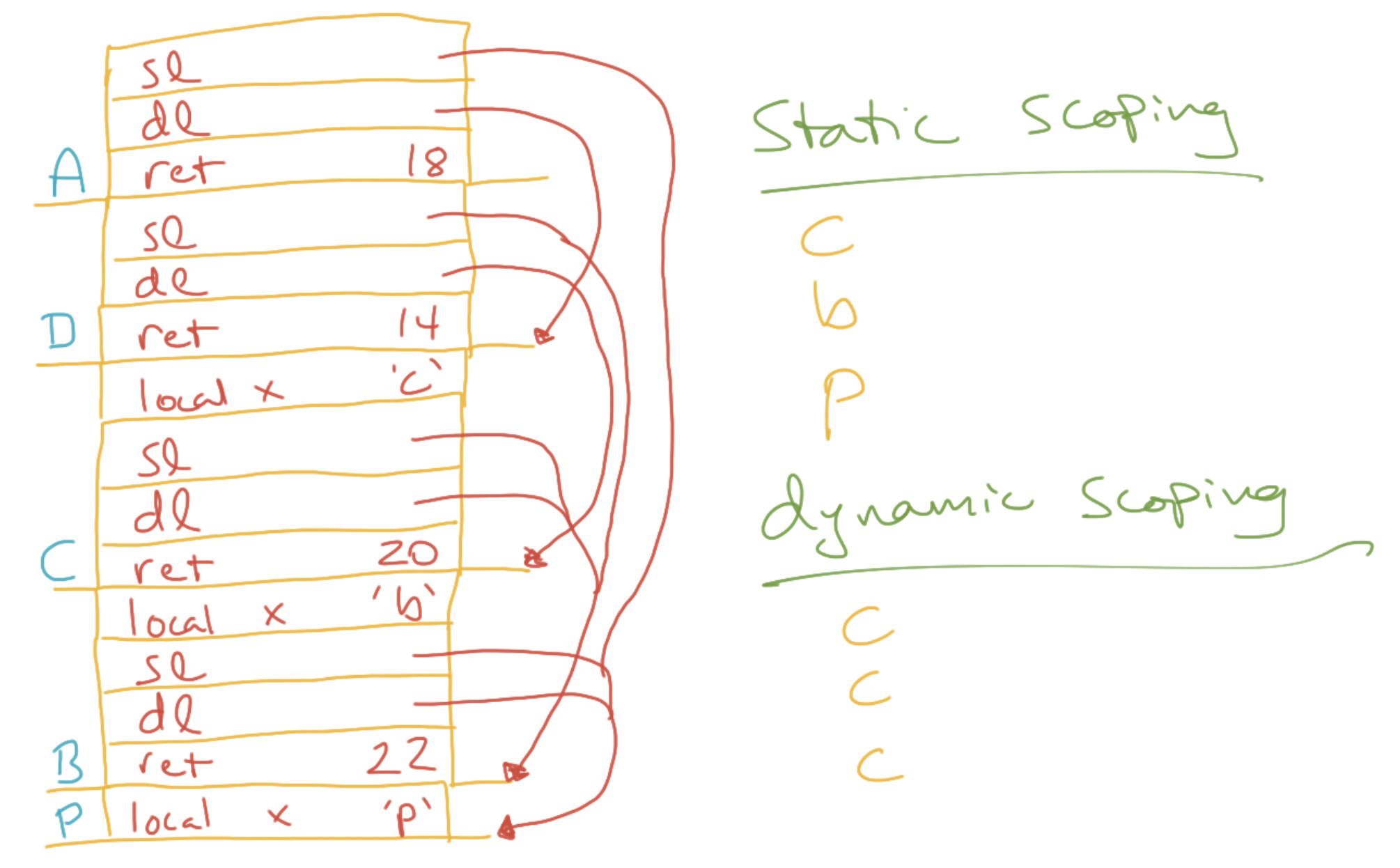
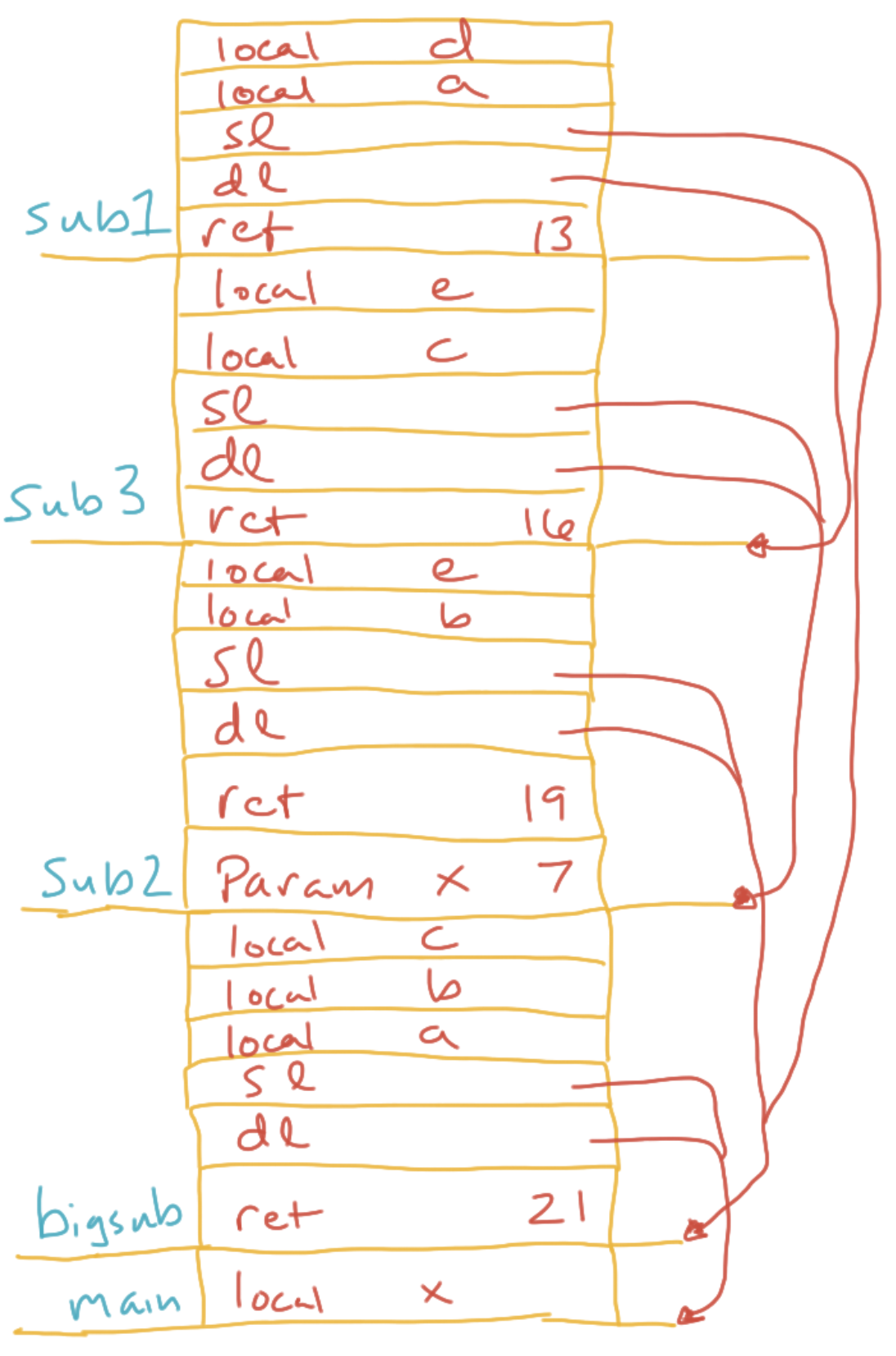
When the compiler encounters a free variable, it works outward through the chain of surrounding scopes to look for the variable’s declaration. The number of scopes it takes to find the declaration is recorded as the chain offset. The variable’s offset within that function’s stack frame is recorded as the local offset. This all happens at compile time.
At runtime, every time a function is called, a static link is inserted in the called function’s stack frame. The static link points to the stack frame of the called function’s outer function—which is not generally the same as the caller. When a free variable is referenced, the chain offset is used to traverse up these static links (the static chain). Then the local offset is used to find the outer function’s variable. The code to do this traversing is all generated at compile time, so the lookups aren’t as slow as they might be.
Dynamic Scoping
Recall that if we look for free variables in the caller rather than in the surrounding scope, we have dynamic scoping. One might implement this flavor of scoping by walking up the dynamic links (the caller’s base pointer) until one encounters a stack frame that has a declaration for the referenced variable. This scheme is called deep access. Since a function’s caller is only known at runtime, the compiler can’t automatically generate code to walk up the dynamic chain. Deep access is slow.
An alternative that allows faster lookup is to maintain a stack for each active variable name in the program. When a function accesses foo, the value is pulled installed off the top of the stack for foo. No traversal of the dynamic chain is necessary. However, when the function returns, the stacks for all of its local variables must be popped.
To be perfectly honest, I don’t know why we still talk about dynamic scoping. One of its benefits is that we can effectively pass data to functions without using parameters, but even this is not a clear benefit.
Exercises
To illustrate how these scope lookups might be implemented, let’s work through a couple of exercises and draw the changing stack.
A
01 program P() {
02
03 var x = 'p'
04
05 function A() {
06 println(x)
07 }
08
09 function B() {
10 var x = 'b'
11 function C() {
12 var x = 'c'
13 println(x)
14 D()
15 }
16 function D() {
17 println(x)
18 A()
19 }
20 C()
21 }
22 B()
23 }
B
01 function main() {
02 var x
03 function bigsub() {
04 var a, b, c
05 function sub1() {
06 var a, d
07 a = b + c // 1
08 }
09 function sub2(x) {
10 var b, e
11 function sub3() {
12 var c, e
13 sub1()
14 e = b + a // 2
15 }
16 sub3()
17 a = d + e // 3
18 }
19 sub2(7)
20 }
21 bigsub()
22 }
See you next time!
