CS 430: Lecture 9 – Abstraction and Object-oriented Programming
Dear students,
Computer scientists spend considerable time tinkering under the hood of their systems. Their clients, however, are happy to only have a few buttons to push to make those systems work. A simpler view of a complex system is called an abstraction. When a humane abstraction is available, clients can ignore irrelevant and low-level details and focus on the features that matter to their task. Today we examine forms of abstraction that organize and simplify our code for the benefit of our clients.
Types of Abstraction
Our code can be abstracted in several ways. We’ve already examined functions. A function is a procedural abstraction. In a clean procedural abstraction, the caller of a function is only concerned with the parameters and return values, not with the underlying process. Programs themselves are procedural abstractions that can be composed in the shell or through a process API.
When we clump data and its related functions together, we have a data abstraction. Classes are a prime example of a data abstraction. Polymorphic functions also rely on data abstractions in order to serve many different types of data.
Some features of our languages are meant to help organize our code. Let’s call such a feature a grouping abstraction. Examples include packages, namespaces, static classes, and modules. A grouping abstraction gathers together types, data, and subprograms related to a theme. If we don’t need any of a group’s entities, we can ignore it.
Most of our discussion will be centered around data abstraction, but some of the ideas we hit upon will apply to the other forms as well.
Abstract Data Types
Computer scientists have a toolbox of useful data abstractions called abstract data types (ADTs). These include lists, stacks, sets, maps, and even floating point numbers. An ADT defines a set of values and the operations that it supports, but no mention is made of its representation or how its operations are implemented.
When we realize an ADT by choosing a representation and implementing its operations, we have a concrete data type. Some of the ideals of the ADT might be lost since we’re dealing with the constraints of memory and numeric precision. Both ArrayList and LinkedList are concrete data types that implement the list ADT. Both HashMap and TreeMap are concrete data types that implement the map ADT. Both float and double are concrete data types that implement the floating point number ADT.
Many of our languages allow us to define our own data types and advertise their interfaces as ADTs. Let’s discuss a few features our languages provide to help us form ADTs.
Encapsulation
The grouping together of related code and data is called encapsulation. Some groupings are based on syntactic structures. Examples include namespaces in C++ and C#, packages in Java, modules in Ruby and JavaScript. Classes, interfaces, structs are also grouping mechanisms. Other groupings are based on files. Examples include C header files and ad hoc modules based only on the file system.
Encapsulation offers several advantages across the design space of our languages:
- It organizes our code and focuses our attention.
- It allows separate compilation, which improves build speed.
- It makes us less vulnerable to name collisions.
Programming linguists categorize encapsulation schemes on several dimensions:
- Physical encapsulation schemes put all grouped code into a contiguous syntactic unit. Logical encapsualtion allows non-contiguousness. For example, the definition of a class may be spread across many files.
- In a naming encapsulation, the grouping is named and the name is used to access the encapsulated items. In a non-naming encapsulation, no name is assigned to the grouping.
- Grouping-only encapsulation schemes bundle items together but leave the bundled items public. Information hiding schemes allow some items to be private.
Information Hiding
Some of the implementation of an ADT should not be available to clients. Making these implementation details private or inaccessible is called information hiding.
Keeping an object’s state private should be our default behavior. If the client has direct access to the state, the client may put our object into a situation that should not be legal.
For example, consider this Vector2 class:
class Vector2 {
constructor(x, y) {
this.x = x;
this.y = y;
this.length = Math.sqrt(x * x + y * y);
}
}
If the client reaches in and modifies x, the length property may no longer be accurate. JavaScript doesn’t give us many tools for hiding information. Ruby forces all instance variables to be private. Other languages allow us to mark individual items as public, private, or protected.
To control access to an item that has been marked private, we provide accessor methods. Getters allow clients to read the value of a property. Setters allow clients to update the value. Some accessors don’t even have a backing variable.
class Vector2 {
constructor(x, y) {
this.x = x;
this.y = y;
}
get length() {
return Math.sqrt(x * x + y * y);
}
set length(newLength) {
const oldLength = this.length();
this.x = this.x / oldLength * newLength;
this.y = this.y / oldLength * newLength;
}
}
const v = new Vector2(10, 0);
v.length = 5;
Examples
To test the soundness of a taxonomy, we should fit the systems with which we’re familiar into it.
| Physical | Logical | |
|---|---|---|
| naming | Java classes and packages | Ruby classes and modules, C++ namespaces |
| non-naming | .c, .cpp, .h files, JavaScript modules | |
| grouping only | .h files | Ruby modules, C++ namespaces |
| information hiding | .c or .cpp files, Java classes and packages | Ruby classes |
The Charade of Classes
Did you know that in the early days of C++, it was just a thin veneer over C? Classes were just syntactic sugar. We might have had a class that looked like this:
class Hero {
public:
Hero(char *name, int hp) {
this->name = strdup(name);
this->hp = hp;
}
void cure(int boost) {
hp += boost;
}
private:
char *name;
int hp;
}
This code would get compiled down to C, where classes weren’t a thing. But C does have structs, so Hero would get turned into one of those:
struct Hero {
char *name;
int hp;
}
What about the methods of Hero? They’d get turned into regular C functions:
void cure(struct Hero *hero, int boost) {
hero->hp += boost;
}
Notice how the invoking object became the first parameter. But it wasn’t called hero. It was called this:
void cure(struct Hero *this, int boost) {
this->hp += boost;
}
When the compiler uses the compile-time type to figure out what method to call and wires the call into machine code, that’s called static dispatch.
What happened when we instantiated an object, like this?
Hero *frank = new Hero("Frank", 260);
It turned into code like this:
void initialize_hero(struct Hero *this, char *name, int hp) {
this->name = strdup(name);
this->hp = hp;
}
int main() {
struct Hero *frank = (struct Hero *) malloc(sizeof(struct Hero));
initialize_hero(frank, "Frank", 260);
// ...
}
Those two lines in main were particularly dear to Bjarne Stroustrup, the inventor of C++. In C, it was very easy to allocate space for an instance of a data structure but then forget to initialize it. Stroustrup believed that allocation and initialization should not be separate steps, that “resource acquisition is initialization” (RAII). Many other languages adopted a similar approach. To construct an object is to be allocate memory for it and assign the object’s initial state.
Dynamic Dispatch via Vtables
Eventually, C++ became distinct enough that Stroustrup developed a compiler that took C++ directly to machine code. One of the features of C++ that warranted a custom compiler was subtype polymorphism. For subtype polymorphism to work in languages like Java and C++, we need to figure out what version of a method to call. In a polymorphic setting, we don’t exactly know what the type of the object is until runtime, so we call the process of figuring out the method dynamic dispatch.
Computer graphics pioneer Jim Blinn wrote a column in 1990s when C++ was gaining in popularity, and he dismissed polymorphism, saying he’d been doing something like it in Fortran for the longest time. Here’s his polymorphism in Fortran:
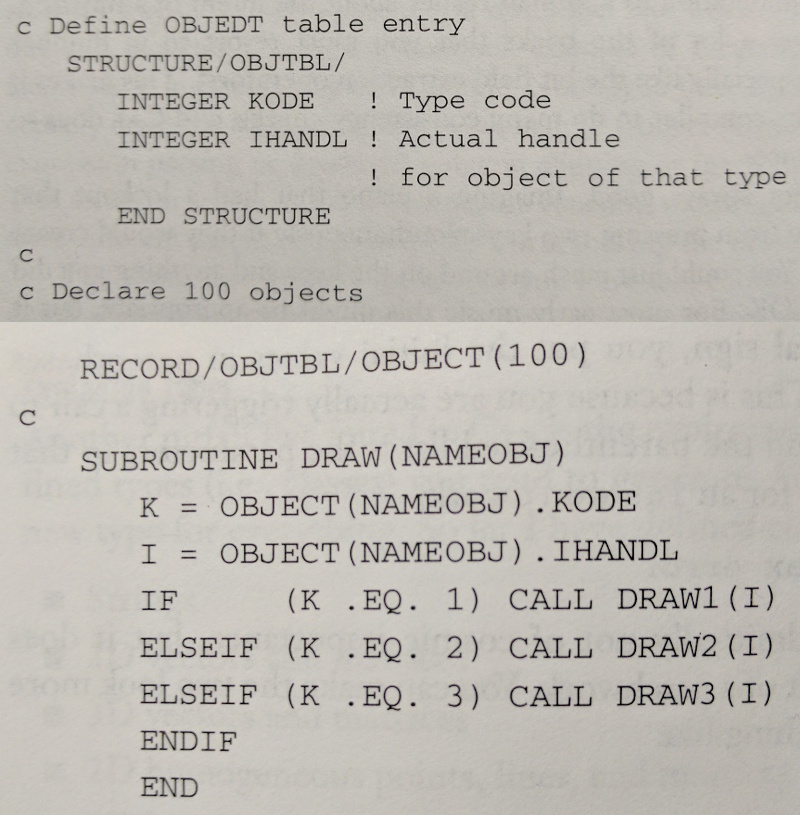
Structure OBJTBL is a pair of a type tag and a pointer. Subroutine DRAW is the polymorphic conductor code. It walks through a conditional ladder, inspects the type tag, and dispatches accordingly.
If this was how dynamic dispatch was implemented today, its designer would have been eaten alive on Reddit and Stack Overflow. Why? For one, the conductor code is full of conditional statements. We saw in computer architecture that conditional statements thwart pipelining. For two, every time we add a new type to our hierarchy, we have to go back to the conductor code and update it. We’d really like to avoid touching code once it’s working. We tend to mess stuff up. There’s that saying, “separate that which changes from that which doesn’t.” Thankfully, dynamic dispatch is implemented differently.
Let’s look at the memory footprint of some C++ classes. We’ll start with an int wrapper:
#include <iostream>
class A {
public:
A(int a) :
a(a) {
}
void foo() {}
private:
int a;
};
int main(int argc, char **argv) {
A a(3);
return 0;
}
Let’s compile this and inspect a with the debugger. Here’s the g++/lldb magic that makes that possible:
g++ -std=c++11 -g footprint.cpp
lldb ./a.out
(lldb) breakpoint set --name main # break on main
(lldb) run # run until breakpoint
(lldb) n # step through next statement
(lldb) print sizeof(a) # Probably 4 or 8
(lldb) x/4ub &a # Examine the 4 bytes of a
When I run this on my macOS laptop, I get this output:
(lldb) print sizeof(a) $1 = 4 (lldlldb) x/4ub &a 0x7fff5fbfe918: 3 0 0 0
What’s the endianness of my machine?
What happens when we add some more state? Like an array of characters:
class A {
public:
A(int a) :
a(a) {
}
void foo() {}
private:
char cs[3] = {'a', 'b', 'c'};
int a;
};
When I run this on my macOS laptop, I get this output:
(lldb) print sizeof(o) $1 = 8 (lldb) x/8ub &o 0x7fff5fbfe918: 97 98 99 0 3 0 0 0
The char[] is padded so that a has a word-aligned address.
Let’s add a subclass:
class B : public A {
public:
B(int a, float b) :
A(a),
b(b) {
}
private:
float b;
};
int main(int argc, char **argv) {
A a(3);
B b(10, 3.14159);
return 0;
}
Class A hasn’t changed. But let’s inspect our instance of B:
(lldb) print sizeof(b) $0 = 12 (lldb) x/12ub &b 0x7fff5fbfe908: 97 98 99 0 3 0 0 0 0x7fff5fbfe910: -48 15 73 64
This output tells us that the first bytes of a B instance are its A foundation. We also see the wild bytes of the float that come after.
Notice that no space in these objects is reserved for code. Code doesn’t live in the object; it is shared across all objects and lives in the text segment of the process’s memory space. We package code and data together in an object-oriented programming language, but the code and data are separated within the memory of the machine.
What do you suppose happens if we have this assignment?
A ab = b;
You’re right. The extra bytes of b get chopped off. This is called object slicing.
Let’s make foo a virtual function:
virtual void foo() {}
What effect does this have on a and b? Let’s check:
(lldb) print sizeof(a) $0 = 16 (lldb) print sizeof(b) $1 = 24 (lldb) x/16ub &a 0x7fff5fbfe910: 32 16 0 0 1 0 0 0 0x7fff5fbfe918: 97 98 99 0 3 0 0 0 (lldb) x/24ub &b 0x7fff5fbfe8f8: 72 16 0 0 1 0 0 0 0x7fff5fbfe900: 97 98 99 0 3 0 0 0 0x7fff5fbfe908: -48 15 73 64 0 0 0 0
The objects are bigger. Both have 8 new bytes at their beginning. That, my friends, is a pointer to each class’s virtual table or vtable, the vehicle by which fast dynamic dispatch happens. Object b also gets an extra 4 bytes at the end. I believe this is used to ensure that the vtable pointers are aligned to 8-byte boundaries when we have a sequence of B instances back to back, as in an array or struct.
Let’s examine a class hierarchy (courtesy of Stroustrup) and see how these virtual tables are laid out:
class A {
public:
virtual void f();
virtual void g(int);
virtual void h(double);
void i();
int a;
};
class B : public A {
public:
void g(int);
virtual void m(B*);
int b;
};
class C : public B {
public:
void h(double);
virtual void n(C*);
int c;
}
int main() {
A o;
B p;
C q;
return 0;
}
The vtable of A looks like this:
| index | Function | Address |
|---|---|---|
| 0 | f | &A::f |
| 1 | g | &A::g |
| 2 | h | &A::h |
Method i gets no entry, because it is not virtual.
The vtable of B looks like this:
| index | Function | Address |
|---|---|---|
| 0 | f | &A::f |
| 1 | g | &B::g |
| 2 | h | &A::h |
| 3 | m | &B::m |
Class B overrides g and adds m. Its other entries just point to the versions from A.
The vtable of C looks like this:
| index | Function | Address |
|---|---|---|
| 0 | f | &A::f |
| 1 | g | &B::g |
| 2 | h | &C::h |
| 3 | m | &B::m |
| 4 | n | &C::n |
These vtables are stored once per class—they’re static. Each instance of A, B, or C has an implicit instance variable pointing to its class’ vtable. We’ll call that member vptr. An instance of A is laid out like this in memory:
| vptr |
| a |
An instance of B is laid out like this in memory:
| vptr |
| a |
| b |
An instance of C is laid out like this in memory:
| vptr |
| a |
| b |
| c |
Here’s a more graphic representation of memory:
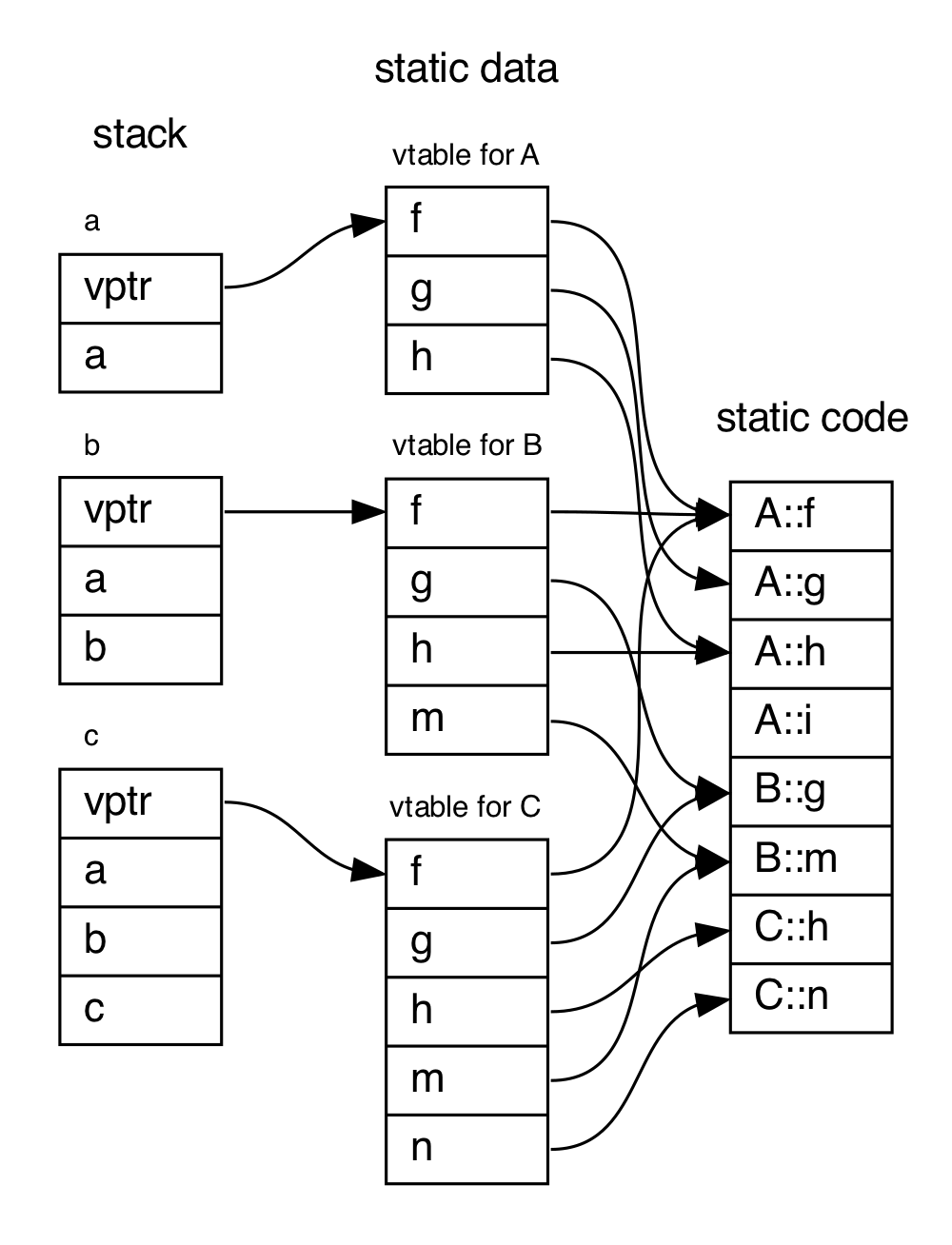
Now, suppose we have a piece of conductor code that takes in a pointer to A, but under the hood the object is an instance of C:
void conduct(A *p) {
p->g(11);
}
What exactly has to happen here to get the right code running?
- We must conjure up
p‘svptr. - In the table pointed to by
p->vptr, we must locate the address of the code forg, which has index 1. - We must call that code with both the invoking object and 11 as parameters.
Under the hood, this invocation turns into a crazy indirect memory lookup. We get a function pointer from the vtable pointed to by the object and call it:
(*(*p->vptr)[1])(p, 11);
So, subtype polymorphism is made fast at runtime through a table lookup. No conditionals are needed. Is this indirection free? No, because there are memory reads. Will these memory reads be fast? The vtables will likely be stored in cache if they are frequently accessed. They are small and there’s only one per class. The object is also likely to be in cache if we’re operating on it.
C++ isn’t the only language to use vtables. Consider this statement from the Java Virtual Machine specification:
The Java Virtual Machine does not mandate any particular internal structure for objects.In some of Oracle’s implementations of the Java Virtual Machine, a reference to a class instance is a pointer to a handle that is itself a pair of pointers: one to a table containing the methods of the object and a pointer to the Class object that represents the type of the object, and the other to the memory allocated from the heap for the object data.
Multiple Inheritance
Many of our object-oriented languages only allow a class to have one superclass. With only one superclass, the structure of the subclass is easy to determine: just tack its state after the superclass state in the class instance record.
What if you wanted a class to have two superclasses? Something like ClickableAnimatedSprite? Well, the class instance record would have to hold both parents. Instead of a simple linear structure, the class instance record would have to hold a hierarchy. Additionally, there is the possibility that both superclasses might have a method of the same name. When the subclass calls the method, which superclass’s version is called? In C++, you must qualify the call with the intended superclass:
ThatParent::foo();
Java forbids multiple inheritance. One can implement multiple interfaces, however. In early Java, interfaces didn’t have any method implementations, so a shared method wasn’t an issue. In Java 8, interfaces can have default implementations. You must disambiguate through qualified access, just as with C++.
What if both superclasses themselves have a common superclass? Your inheritance structure will look something like this:
A A | | B C \ / D
What we want is this:
A / \ B C \ / D
This is called the dreaded diamond pattern, and C++ is one of the few languages that allows you to achieve it. You unite the shared base object by using virtual inheritance:
class Grandparent {}
class ParentA : virtual Grandparent {}
class ParentB : virtual Grandparent {}
class Child : public ParentA, ParentB {
// construct the whole hierarchy manually
Child() : Grandparent(), ParentA(), ParentB() {}
}
The compiler expects the subclass to manually steer the construction of the superclasses.
Templates vs. Generics
Another way we abstract data is by writing one structure that serves many types. Here’s how we might make a 2-tuple in C++ using templates:
class Tuple<typename T, typename U> {
public:
Tuple(T first, U second) : first(first), second(second) {}
private:
T first;
U second;
}
The C++ compiler will generate a new version of this class for every type combination that it encounters. There’s no mechanism for compiling the class ahead of time. It needs to stay in its source form if others are to be able to access it.
The Java folks decided to take a different approach, one that didn’t sprinkle so many similar versions of the templated structures. Here’s our 2-tuple written using Java generics:
class Tuple<T, U> {
private T first;
private U second;
public Tuple(T first, U second) {
this.first = first;
this.second = second;
}
}
Behind the scenes, the compiler generates one bytecode representation of Tuple in which the type parameters have been replaced with real types determined by their bounds. If the type parameters are not bounded, the parameters are replaced with Object. This erasure leads to this non-generic version of Tuple:
class Tuple {
private Object first;
private Object second;
public Tuple(Object first, Object second) {
this.first = first;
this.second = second;
}
}
Java piggybacks on subtype polymorphism to implement parametric polymorphism. This means that only classes can be type parameters. We can’t have a Pair<int, boolean>, for example. But we can have Pair<Integer, Boolean>.
Reflection
The book sneaks in a discussion of reflection, though it doesn’t really fit in with the other topics we’ve looked at today. Reflection is the ability for code to ask questions about itself. One can ask a method with its parameters are, what exceptions it throws, and how visible it is. One can ask a class what its instance variables and methods are. Reflection allows us to do some interesting things, like run unit test runner. Here we ask the class for all its methods that start with the string "test" and automatically run them:
import java.lang.reflect.Method;
public class Tester {
public static void testA() {
System.out.println("a");
}
public static void testB() {
System.out.println("b");
}
public static void testC() {
System.out.println("c");
}
public static void helper() {
System.out.println("helper");
}
public static void main(String[] args) {
for (Method method : Tester.class.getMethods()) {
try {
if (method.getName().startsWith("test")) {
method.invoke(null);
}
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
Conclusion
See you next time!

P.S. It’s time for a haiku!
Who moves the clock’s hands?
It does, thank goodness it does
I don’t have the time